In Process
一、单项选择题
第 1 题
中国的国家顶级域名是()
A. .cn
B. .ch
C. .chn
D. .china
选A。域名用
.分割,最右边的是顶级域名,中国的国家顶级域名是.cn。
第 2 题
二进制数 11 1011 1001 0111 和 01 0110 1110 1011 进行逻辑与运算的结果是()。
A. 01 0010 1000 1011
B. 01 0010 1001 0011
C. 01 0010 1000 0001
D. 01 0010 1000 0011
选D。两位都为1,结果为1,否则为0。
| 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | |
| & | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| = | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
第 3 题
一个 32 位整型变量占用()个字节。
A. 32
B. 128
C. 4
D. 8
选C。解析:在计算机中,数据存储的单位是字节(Byte),一个字节等于8位(bit)。一个32位整型变量,就是指这个变量可以存储32个二进制位,即4个字节。所以,一个32位整型变量占用4个字节。
第 4 题
若有如下程序段,其中 s、a、b、c 均已定义为整型变量,且 a、c 均已赋值(c 大于 00)
1 | s = a; |
则与上述程序段功能等价的赋值语句是()
A. s = a - c;
B. s = a - b;
C. s = s - c;
D. s = b - c;
选A。解析:在程序段中,首先将变量
a的值赋给变量s,然后通过一个循环对s进行操作。循环的次数由变量c决定,每次循环都会使s的值减1。如果我们要找到一个赋值语句,其功能与上述程序段等价,那么我们需要找到一个表达式,该表达式在执行后也会使
s的值减1,并且减的次数等于c。选项A中的表达式
s = a - c;符合这个要求。在程序段中,每次循环都会执行s = s - 1,这会使s的值减去1。由于循环的次数由c决定,因此总共会进行c次减法操作,这就满足了题目的要求。
第 5 题
设有 100 个已排好序的数据元素,采用折半查找时,最大比较次数为()
A. 7
B. 10
C. 6
D. 8
选A。需要$\log _2 100$次,2的n中大于100的最小整数是$2^7 = 128$,故最大次数为7。
第 6 题
链表不具有的特点是()
A. 插入删除不需要移动元素
B. 不必事先估计存储空间
C. 所需空间与线性表长度成正比
D. 可随机访问任一元素
选D。解析:链表是一种常见的数据结构,它由一系列节点组成,每个节点包含两部分:数据域和指针域。数据域用于存储数据元素,而指针域用于存储下一个节点的地址。
选项A是正确的,因为链表的插入和删除操作只需要修改相邻节点的指针域,而不需要移动其他元素。这使得链表在插入和删除操作上比线性表更加高效。
选项B也是正确的,因为链表不必预先分配固定大小的存储空间。每当需要添加一个新元素时,只需分配一个新的节点,并将其添加到链表的末尾即可。这使得链表在内存使用上更加灵活。
选项C也是正确的,因为链表所需的存储空间与线性表的长度成正比。每个节点都需要额外的存储空间来存储指针域,而链表中的元素数量就是节点的数量。
然而,选项D是不正确的,因为链表不能随机访问任一元素。为了访问链表中的任一元素,必须从链表的头部开始遍历,直到找到目标元素或者到达链表的尾部。这种顺序访问的方式使得链表在随机访问上的性能较差于线性表。
第 7 题
把 8 个同样的球放在 5 个同样的袋子里,允许有的袋子空着不放,问共有多少种不同的分法?()
提示:如果 8 个球都放在一个袋子里,无论是哪个袋子,都只算同一种分法。
A. 22
B. 24
C. 18
D. 20
选C。
4个空袋:1种
3个空袋:1+7,2+6,3+5,4+4
2个空袋:1+1+6,1+2+5,1+3+4,2+2+4,2+3+3
1个空袋:1+1+1+5,1+1+2+4,1+1+3+3,1+2+2+3,2+2+2+2
没有空袋:1+1+1+1+4,1+1+1+2+3,1+1+2+2+2
第 8 题
一棵二叉树如右图所示,若采用顺序存储结构,即用一维数组元素存储该二叉树中的结点(根结点的下标为 1,若某结点的下标为 i,则其左孩子位于下标 2i 处、右孩子位于下标2i+1 处),则该数组的最大下标至少为()。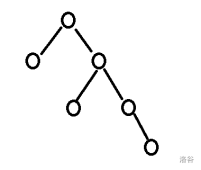
A. 6
B. 10
C. 15
D. 12
选C。
第 9 题
100 以内最大的素数是()。
A. 89
B. 97
C. 91
D. 93
选B。
第 10 题
319 和 377 的最大公约数是()。
A. 27
B. 33
C. 29
D. 31
选C。可以用辗转相除法。
- $377 % 319 = 58$
- $319 % 58 = 29$
- $58 % 29 = 0$
故答案为29。
第 11 题
新学期开学了,小胖想减肥,健身教练给小胖制定了两个训练方案。
- 方案一:每次连续跑 3 公里可以消耗 300 千卡(耗时半小时);
- 方案二:每次连续跑 5 公里可以消耗 600 千卡(耗时 1 小时)。
小胖每周周一到周四能抽出半小时跑步,周五到周日能抽出一小时跑步。
另外,教练建议小胖每周最多跑21公里,否则会损伤膝盖。
请问如果小胖想严格执行教练的训练方案,并且不想损伤膝盖,每周最多通过跑步消耗多少千卡?()
A. 3000
B. 2500
C. 2400
D. 2520
选C。3天跑一小时,2天跑半小时,共21公里,1800 + 600 = 2400千卡。
第 12 题
—副纸牌除掉大小王有 52张牌,四种花色,每种花色 13 张。
假设从这 52 张牌中随机抽取 13 张纸牌,则至少()张牌的花色一致。
A. 4
B. 2
C. 3
D. 5
选A。解析:这是一个应用鸽巢原理的问题。鸽巢原理,又称抽屉原理,是组合数学中的一个定理。其基本内容是:如果把$n+1$个物体放入$n$个盒子,那么至少有一个盒子里有两个物体。
在这个问题中,”鸽子”是52张牌,”鸽巢”是4种花色。我们需要从52张牌中抽取13张牌,那么根据鸽巢原理,至少有一个花色的牌数大于等于$\dfrac{13}{4}=3.25$,向上取整得4。
所以至少4张牌的花色一致。
第 13 题
—些数字可以颠倒过来看,例如 0,1,8 颠倒过来还是本身,6 颠倒过来是 9,9 颠倒过来看还是 6,其他数字颠倒过来都不构成数字。
类似的,一些多位数也可以颠倒过来看,比如 106 颠倒过来是 901。假设某个城市的车牌只由 5 位数字组成,每一位都可以取 0 到 9。
请问这个城市最多有多少个车牌倒过来恰好还是原来的车牌?()
A. 60
B. 125
C. 75
D. 100
选C。第1、2位有(0、1、8、6、9)五个数字,第3位有(0、1、8)三个数字,第4、5位由第1、2位决定(如第1位6,则第5位9)。
5 * 5 * 3 = 75
第 14 题
假设一棵二叉树的后序遍历序列为 DGJHEBIFCA,中序遍历序列为 DBGEHJACIF,则其前序遍历序列为()。
A. ABCDEFGHIJ
B. ABDEGHJCFI
C. ABDEGJHCFI
D. ABDEGHJFIC
选B。
1 | graph TB |
第 15 题
以下哪个奖项是计算机科学领域的最高奖?()
A. 图灵奖
B. 鲁班奖
C. 诺贝尔奖
D. 普利策奖
选A。
二、阅读程序
2.1
1 |
|
输入字符串,序号是n的约数的字符,小写转大写。
判断题
1)输入的字符串只能由小写字母或大写字母组成。( × )
2)若将第 8 行的 i = 1 改为 i = 0,程序运行时会发生错误。( √ )
3)若将第 8 行的 i <= n 改为 i * i <= n,程序运行结果不会改变。( × )
4)若输入的字符串全部由大写字母组成,那么输出的字符串就跟输入的字符串一样。( √ )
选择题
5)若输入的字符串长度为 18,那么输入的字符串跟输出的字符串相比,至多有()个字符不同。
A. 18
B. 6
C. 10
D. 1
选B。1、2、3、6、9、18。
6)若输入的字符串长度为(),那么输入的字符串跟输出的字符串相比,至多有 36 个字符不同。
A. 36
B. 100000
C. 1
D. 128
选B。$100000 = 2^5 \times 5^5$,2可以取$2^0, 2^1…2^5$,有6种取法,5有6种取法,共有36种取法。
2.2
1 |
|
假设输入的 n 和 m 都是正整数,x 和 y 都是在 [1, n] 的范围内的整数,完成下面的判断题和单选题:
跟最大匹配问题有点像,详情可参考该文章最大匹配问题——匈牙利算法通俗理解 - 知乎 (zhihu.com)。
两个数组,可以看作二分图,输入x,y配对,最后统计处未匹配的元素个数。
代码的主要逻辑如下:
- 首先,定义了两个整型数组a和b,用于存储每个元素的匹配情况。初始时,所有元素都被标记为未匹配(0)。
- 然后,通过循环读取输入的配对关系,并更新数组a和b中的匹配情况。如果当前配对关系中的两个元素可以互相匹配(即a[x] < y且b[y] < x),则将它们互相匹配,并将原来的匹配关系置为未匹配。
- 最后,遍历数组a和b,统计未匹配的元素个数。
判断题
1)当 m>0 时,输出的值一定小于 2n。( √ )
2)执行完第 27 行的 ++ans 时,ans —定是偶数。( × )
在for循环执行的过程中,ans未统计完,有可能为奇数。
for循环执行完后,ans—定是偶数。
3)a[i] 和 b[i] 不可能同时大于 0。( × )
m = 1,x = 2,y = 2时,
a[i]和b[i]同时为2。
4)若程序执行到第 13 行时,x 总是小于 y,那么第 15 行不会被执行。( × )
不一定能够,如(1, 2)、(1,3)。
选择题
5)若 m 个 x 两两不同,且 m 个 y 两两不同,则输出的值为()
A. 2n−2m
B. 2n+2
C. 2n−2
D. 2n
选A。输出未匹配的值,最终匹配2m个数,一共有2n个数,gu为2n - 2m。
6)若 m 个 x 两两不同,且 m 个 y 都相等,则输出的值为()
A. 2n−2
B. 2n
C. 2m
D. 2n−2m
选A。最终只匹配一对,减去2个。
2.3
1 |
|
将数组b根据数组a的值构造成一棵二叉树,二叉树的节点是b数组的元素。每次在序列中选择a值最小且最靠前的元素作为根,根左侧的序列构建左子树,根右侧的序列构建右子树,递归求解。最后求每个节点值b[i]乘深度depth的和。
判断题
1)如果 a 数组有重复的数字,则程序运行时会发生错误。( × )
如果重复,判断条件是
if (min > a[i]),min == a[i]时不管,找第一个最小值,无影响。
2)如果 b 数组全为 0,则输出为 0。( √ )
选择题
3)当 n=100 时,最坏情况下,与第 12 行的比较运算执行的次数最接近的是:()。
A. 5000
B. 600
C. 6
D. 100
选A。最坏情况,每次min都在最左边或最右边,每层只少一个点,即比较次数每层少1,总次数为$100 + 99 + … + 1 = 5050$
4)当 n=100 时,最好情况下,与第 12 行的比较运算执行的次数最接近的是:()。
A. 100
B. 6
C. 5000
D. 600
选D。最好情况,每次min都在中间,要分$log_2100$次,即深度,大概为6,每层大概执行100次。
5)当n=10 时,若 b 数组满足,对任意 0≤i<n,都有 b[i] = i + 1,那么输出最大为()。
A. 386
B. 383
C. 384
D. 385
选D。

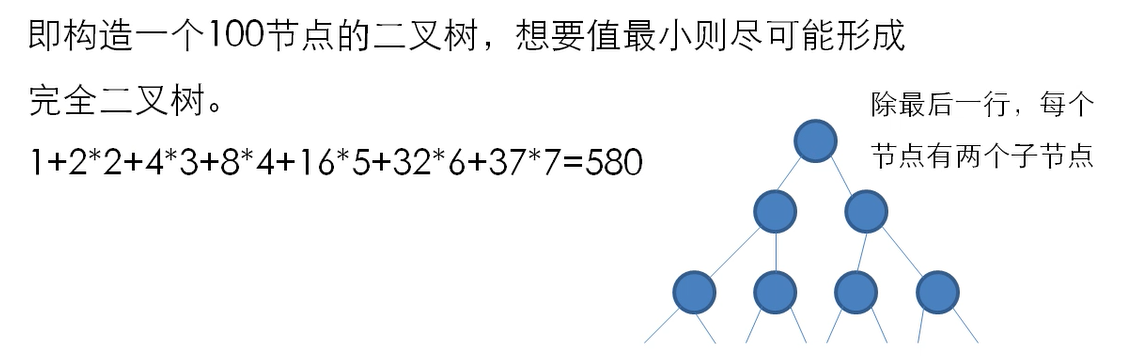
6)当 n=100 时,若 b 数组满足,对任意 0≤i<n,都有 b[i]=1,那么输出最小为()。
A. 582
B. 580
C. 579
D. 581
选B。
三、完善程序
3.1 矩阵变幻
有一个奇幻的矩阵,在不停的变幻,其变幻方式为:
数字 0 变成矩阵
1 | 0 0 |
数字 1 变成矩阵
1 | 1 1 |
最初该矩阵只有一个元素 0,变幻 n 次后,矩阵会变成什么样?
例如,矩阵最初为:[0];
矩阵变幻 1 次后:
1 | 0 0 |
矩阵变幻 2 次后:
1 | 0 0 0 0 |
输入一行一个不超过 10 的正整数 n。输出变幻 n 次后的矩阵。
试补全程序。
提示:
<< 表示二进制左移运算符,例如 $(11)_2(11)_2$ << 2 = $(1100)_2$
而 ^ 表示二进制异或运算符,它将两个参与运算的数中的每个对应的二进制位—进行比较,若两个二进制位相同,则运算结果的对应二进制位为 0 ,反之为 1。
1 |
|
①处应填()
A. n%2
B. 0
C. t
D. 1
选C。
②处应填()
A. x-step,y-step
B. x,y-step
C. x-step,y
D. x,y
选D。举例:一开始为0,
n = 1。
1 | 0 0 |
起始坐标为(0,0)
第一行:第一个0为当前坐标,第二个0为(0,0 + 1)
第二行:第一个0为(0 + 1,0 ),第二个1为(0+1,0+1)
代码中已有右边 和 下边两个坐标,还差 当前坐标 和 右下坐标。
③处应填()
A. x-step,y-step
B. x+step,y+step
C. x-step,y
D. x,y-step
选B。
④处应填()
A. n-1,n%2
B. n,0
C. n,n%2
D. n-1,0
选B。n是矩阵大小,初始为n。
前3个递归调用函数参数为
t,最后一个调用参数为!t,t的初始值为0。
⑤处应填()
A. 1<<(n+1)
B. 1<<n
C. n+1
D. 1<<(n-1)
选B。
n = 1:size = 2
n = 2: size = 4
size为$2^n$,位运算
1 << n
3.2 计数排序
计数排序是一个广泛使用的排序方法。下面的程序使用双关键字计数排序,将 n 对 10000 以内的整数,从小到大排序。
例如有三对整数 (3,4)、(2,4)、(3,3),那么排序之后应该是 (2,4)、(3,3)、(3,4) 。
输入第一行为 n,接下来 n 行,第 i 行有两个数 a[i] 和b[i],分别表示第 i 对整数的第一关键字和第二关键字。
从小到大排序后输出。
数据范围 1<n<$10^7$,1<a[i],b[i]<$10^4$。
提示:应先对第二关键字排序,再对第一关键字排序。数组 ord[] 存储第二关键字排序的结果,数组 res[] 存储双关键字排序的结果。
试补全程序。
1 |
|
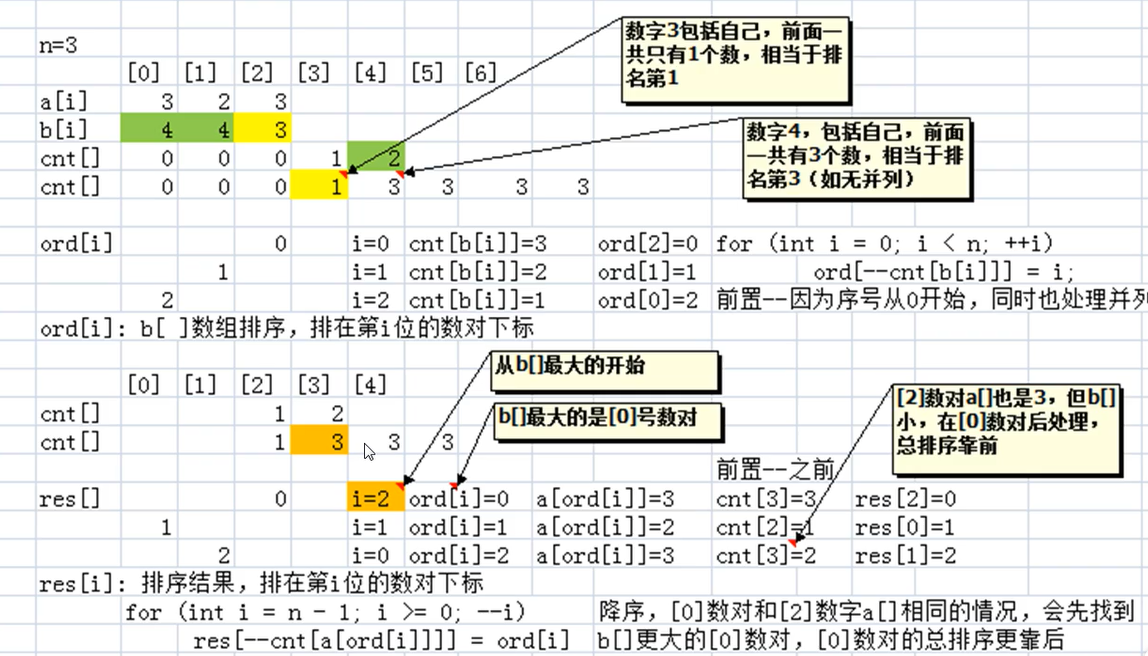
①处应填()
A. ++cnt[i]
B. ++cnt[b[i]]
C. ++cnt[a[i] * maxs + b[i]]
D. ++cnt[a[i]]
选B。先对第二关键字桶计数。
②处应填()
A. ord[--cnt[a[i]]] = i
B. ord[--cnt[b[i]]] = a[i]
C. ord[--cnt[a[i]]] = b[i]
D. ord[--cnt[b[i]]] = i
选D。升序排序。
③处应填()
A. ++cnt[b[i]]
B. ++cnt[a[i] * maxs + b[i]]
C. ++cnt[a[i]]
D. ++cnt[i]
选C。对第一关键字桶计数。
④处应填()
A. res[--cnt[a[ord[i]]]] = ord[i]
B. res[--cnt[b[ord[i]]]] = ord[i]
C. res[--cnt[b[i]]] = ord[i]
D. res[--cnt[a[i]]] = ord[i]
选A。
⑤处应填()
A. a[i], b[i]
B. a[res[i]], b[res[i]]
C. a[ord[res[i]]],b[ord[res[i]]]
D. a[res[ord[i]]],b[res[ord[i]]]
选B。res[i]记录的是第i个数在原序列的位置。
参考


